Measuring digital campaign rally participation: how to track livestream views using python.
Fork this project in Github here
Get the datahere
View the compiled visualizationshere

Leni Robredo and Kiko Pangilinan's massive Pampanga rally crowd, April 12, 2022.
- JCP: The election results are out by the time I post this blog entry. Apologies for posting this quite late, I just felt like I had to take a break and process everything. Although the campaigns are long over, I hope this mini-project inspires the data science community to document and analyze other massive public digital events in the future.
It was during the middle of the 2022 PH election campaign period that we have witnessed multiple campaign rallies with massive crowds from both Robredo-Pangilinan (TRoPa) and Marcos-Duterte (Uniteam) camps. These events were livestreamed in various social media platforms, which are also equally well-attended.
What sparked my data science instincts in particular was TRoPa’s Pampanga rally. Netizens started sharing screenshots of the livestream containing the peak live views during the event. There were questions and heated debates about onsite crowd estimates for these campaigns, but hardly anyone contends the legitimacy of the screenshots since the host platforms count the number of viewers in real-time.
But how do we ensure that these screenshots are reliable? Instead of relying on past posts containing livestream screenshots, I thought, why not tap right into the live video itself and collect live views data as the event happens, from start to finish?
This is what I did for this project.
Why monitor livestream views?#
The usual election-related data-science projects are centered on sentiment analysis of post contents. Most of these gather data from Twitter, which is easy to scrape given the many open source projects available to do this.
However, I think we exert more data vigilance on Facebook, the country’s most widely-used social media platform. By tracking Facebook livestream views, I provide here a less-tapped space for us data scientists to involve ourselves in election discourse, for a couple of important reasons:
-
Livestreams made campaign events more inclusive. Truth be told–the people that would be able to attend rallies in person are those who have the resources and long time to spare. A large percentage of people can’t afford to take a work day off or forego limited rest time to attend a rally. It is more convenient and cost-effective to express support by viewing a livestream.
-
The number of views also provide a measure of a candidates’s digital political machinery. The number of comments and shares of the video can serve as an estimate, but such active participation could be prone to spam behavior. By getting the views as counted by Facebook servers, we get a measure of passive participation that could possibly translate to votes.
OK, now how do we track livestream views?#
You can do it manually, but it is very tedious. Here is a screenshot of a livestream webpage:
Livestream screenshot sample. PII of comments from accounts are redacted
To monitor the views, you will have to take note of the current live views number at the top left and record the timestamp when it happened. But there is a limit to how fast and how long a human can reasonably do this. The person must be attentive because the view count refreshes quite fast (<30s) and persistent because livestreams go on for at least 3 hours.
Thankfully, web browser tools like Selenium exists to do this tedious work. A python code can control the livestream video in the Selenium browser, extract the viewer count in realtime, and take minutely snapshots of the video itself as future reference.
Using this approach, I have tracked views from 58 campaign Facebook livestreams of Marcos, Robredo and Moreno’s campaign rallies.
Writing the code#
1. Loading the stream#
The first part of the code is a helper function that parses and saves the current live views from the livestream webpage html source.
def job():
#get current datetime and load livestream video in selenium browser
current_dt = pd.Timestamp.now(tz='Asia/Manila').strftime("%Y-%m-%dT%H:%M:%S")
driver.get(url_stream)
#browser waits for 10 seconds or until livestream video appears
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "div[data-pagelet='WatchPermalinkVideo']")))
The function starts by getting the current datetime and loading the livestream link stored in url_stream. To ensure that the livestream page is fully loaded, we use Selenium’s WebDriverWait command to wait 10 seconds, or until div[data-pagelet='WatchPermalinkVideo'] is clickable, .i.e. the video player is loaded.
2. Parsing and storing the views count#
# encode browser rendered html
search_result_source = driver.page_source.encode('utf-8').decode('ascii', 'ignore')
# find anchor string 'people currently wathcing'
views_idx = search_result_source.find('people currently watching')
# get characters around anchor, split text and remove whitespace
num_views_str = search_result_source[views_idx-10:views_idx].split('"')[1].strip()
# append to container list
views_data_raw.append((current_dt,num_views_str))
# printout views data
print(current_dt+': '+num_views_str+ ' views')
Next, we store the livestream html page source in search_result_source and locate the anchor string "people currently watching". The typical way of doing this is to find the correct div tag (through long xpaths), but since Facebook dynamically generates the class names, it is more reliable to find anchor strings that do not change whenever the page is loaded.
The characters right before the anchor string should contain the live views count. We then store the timestamp and the views count in a list.
3. Taking screenshots and saving the data as .csv#
# Take screenshots and save data as csv
# less frequent screenshots at beginning of livestream
mins_interval_ss = 1 if current_dt.split("T")[1]>="18:00:00" else 2
#do these actions at specific minutes
if current_dt.split("T")[1].split(":")[1] in ['%02d' % c for c in np.arange(0,60,mins_interval_ss)]:
#build ss filename and save
fig_fn = "figs/"+event_name+"/ss_"+event_name+'_'+current_dt.replace(":","").replace(" ","").replace("-","")+".png"
driver.get_screenshot_as_file(fig_fn)
#create dataframe from container list and save as csv
df = pd.DataFrame(views_data_raw, columns=['dt','views_K'])
df['views_K'] = df['views_K'].apply(lambda x: float(x.replace("K","")))
df.to_csv('data/'+event_name+"_livestream_views.csv", index=False)
Selenium also has a feature to take a screenshot of the current browser display and save it as an image file. I did this in case people would request some basis for the livestream data. Every 1 or 2 minutes, the screenshot and .csv are saved in the data/ directory.
To manage total file sizes per tracking, fewer screenshots are taken at the start of the livestream (in this case, before 6:00PM).
4. Putting it all together and running at a specified schedule#
#clear sched to remove existing jobs
schedule.clear()
#change until date to a time when youd expect the livestream to end (plus allowance)
current_date = current_dt.split("T")[0]
schedule.every(1).minutes.at(":15").until(current_date+" 23:55").do(job)
while True:
try:
schedule.run_pending()
time.sleep(1)
except Exception as e:
print('ERROR here')
print(e)
continue
I used the python schedule module to schedule the running of the job function. There are a lot of other modules and architectures to do this (cron, Task Scheduler) but this module offers the easiest syntax and is platform-agnostic.
After executing this code, the job function is automatically ran minutely at the specified second (at the 15th second in this example) and needs to be manually stopped when the livestream has ended.
A different starting second must be set for multiple simultaneous livestream trackings to avoid overloading the browser memory (if this is a concern for your local machine.)
How do you make the final livestream views graph?#
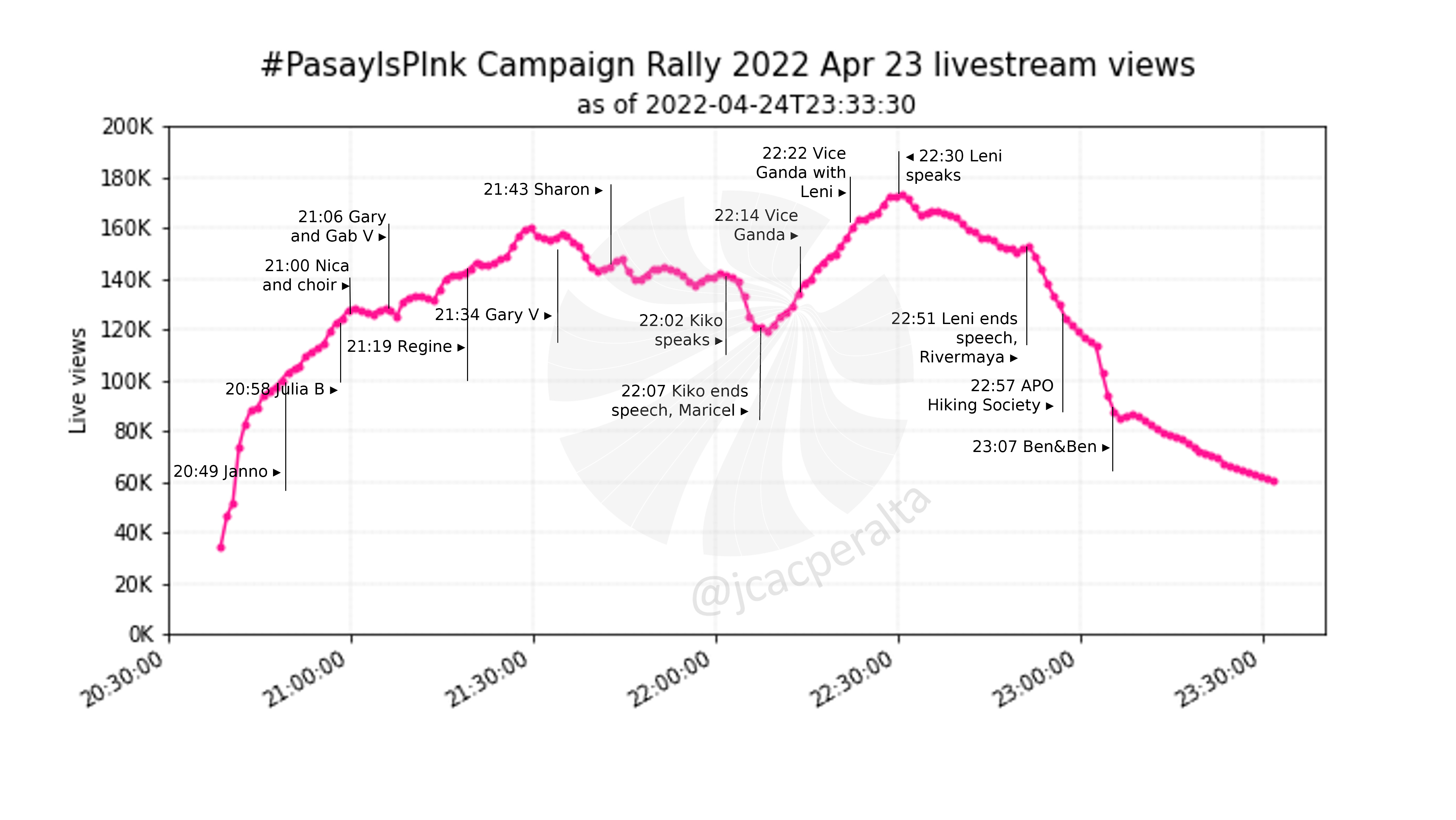
Sample of a minutely livestream views plot with complete annotations.
I presented the result of each livestream views tracking as a simple time series line plot. I annotated this with a line and label marking the minute when a personality is shown in the feed. These annotations are hard to code without overlapping labels, so I did it manually in an editing software.
I have compiled all of the livestream views graph in this thread.
How can we take this further?#
This project systematized the tracking of livestream views and took advantage of browser automation. It is important to note that this code will work on any Facebook livestream, not just for livestreams of candidates or certain election-related pages.
I have thought of ways on how to improve on the current code:
- In my case, one minute is the smallest resolution I could reliably scrape due to memory constraints. Doing subminute schedules will improve the tracking especially when views jump fast.
- I have also observed that there is an appreciable lag between any 2 livestream feeds (one device feed might show a scene that was already shown in another device), and the duration og this lag varies per device. The livestream tracking code can be deployed on multiple devices to produce a minutely error bar that could be useful for further analysis.
- The raw screenshot images contain personally identifiable information (PID) in comments section. Thus, they must be sanitized before uploading. I have redacted the comments sectorn for the screenshot set I have uploaded in the shared folder, but I have yet to figure out how to do this at bulk.
I hope you found this useful. Thanks and see you again in the next blog!